前言
中国mooc是个好网站,有很多免费的课程. 但是它网速不太好,老是会卡屏. 为了帮助中国mooc解决这个问题,我们就来写个爬虫.
分析
- 通过
https://www.icourse163.org/learn/课程名,获取课程id. (课程名例如:SICNU-1002031014)
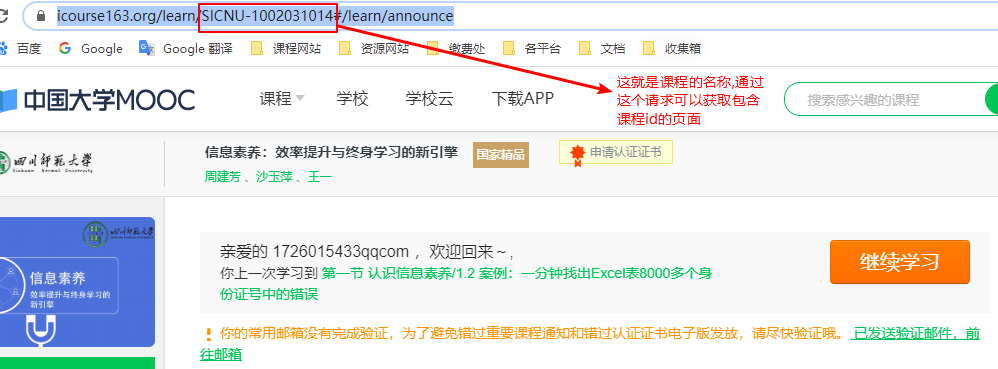

- 通过点击
继续学习的按钮
会向后台请求一个ajax链接http://www.icourse163.org/dwr/call/plaincall/CourseBean.getMocTermDto.dwr. 该链接是一个post请求,参数如下: 
真正重要的就是课程id, 其他无所谓.请求完成后会拿到包含课程所有信息的内容.
- 随便点开一个视频或pdf,可以发现会向后台再次请求一个ajax.
http://www.icourse163.org/dwr/call/plaincall/CourseBean.getLessonUnitLearnVo.dwr,这也是一个post请求.参数如下:
请求的参数就是通过第二步获取的文件中提取出来的. 这样就可以拿到资源的真实地址.
实现
#我们写个中国mooc的爬虫,它是使用ajax请求的,所以要进行分析.
#1. 根据url获取课程id,标题,学校.(重点id,后面要用到)
#2. 根据id获取课程信息列表(该列表中存放了视频和pdf的id,后面就是通过这些id拿到资源)
#3. 根据视频和pdf的id,请求资源的真实地址
#4. 有了真实地址就能下载课程了
import requests
import re
import os
import time
#请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36'
}
#课程首页不完整url(第一步请求链接,这是get请求,需要拼接课程代号,组合成完整的url请求.需要的信息直接从页面提取)
incompleteCourseIndexUrl='http://www.icourse163.org/learn/'
#获取课程信息列表的url(第二步的请求链接,这是一个post请求,课程id就是放进请求体当中获取它的相关信息,返回的是ajax)
courseInfoUrl='http://www.icourse163.org/dwr/call/plaincall/CourseBean.getMocTermDto.dwr'
#获取真实资源地址的url(第三步的请求链接,也是post请求,视频和pdf的id就是放进请求体当中获取它们真实的资源地址,返回的是ajax)
getResourceUrl='http://www.icourse163.org/dwr/call/plaincall/CourseBean.getLessonUnitLearnVo.dwr'
#第一步,根据课程首页获取课程代号(例如:SICNU-1002031014),拼接请求连接.请求获取页面并解析,返回id
def getCourseBase(courseCode):
courseIndexUrl=incompleteCourseIndexUrl+courseCode
res=requests.get(courseIndexUrl,headers=headers)
#提取课程id的
idPattern=re.compile(r'id:(\d+),')
id=re.search(idPattern,res.text).group(1)#id
#提取课程名和学校的正则
basePattern = re.compile(r'<meta name="description" .*?content=".*?,(.*?),(.*?),.*?/>')
baseInfo=re.search(basePattern,res.text)
name=baseInfo.group(1)#课程名
school=baseInfo.group(2)#学校
return id
#第二步,根据课程id获取课程详细信息(信息分为三层,章节信息,小节信息,资源信息都包含在里面),对每个资源信息进行处理
#我们需要的资源信息就是包含在小节信息里面的
def getCourseDetail(courseId):
#请求体中的数据,除了课程id和时间戳,其他都是不变的字段
post_data = {
'callCount': '1',
'scriptSessionId': '${scriptSessionId}190',
'c0-scriptName': 'CourseBean',
'c0-methodName': 'getMocTermDto',
'c0-id': '0',
'c0-param0': 'number:' + courseId,#课程id
'c0-param1': 'number:1',
'c0-param2': 'boolean:true',
'batchId': str(int(time.time()*1000))#当前时间戳
}
res=requests.post(courseInfoUrl,data=post_data,headers=headers)
#请求后的文本,中文编码是\uxxxx形式,所以下面这句话是让文本变成正常中文
courseDetailInfo=res.text.encode('utf-8').decode('unicode_escape')
#提取所有章节的信息(提取名称和id)
chapterPattern=re.compile(r'homeworks=.*?;.+id=(\d+).*?name="(.*?)";')
chapterSet=re.findall(chapterPattern,courseDetailInfo)
#我们把提取的信息写入文件中
with open('MindMap.txt','w',encoding='utf-8') as file:
for index,chapter in enumerate(chapterSet):
file.write('%s \n' % (chapter[1]))#写入章节名并换行
#提取所有小节信息,需要使用到我们章节的id(提取名称与id)
lessonPattern = re.compile(r'chapterId=' + chapter[0] +
r'.*?contentType=1.*?id=(\d+).+name="(.*?)".*?test')
lessonSet=re.findall(lessonPattern,courseDetailInfo)
#把小节信息写入到文件,因为我们是使用章节的id提取出的小节信息,所以可以直接写道章节下面
for subIndex ,lesson in enumerate(lessonSet):
file.write(' %s \n' % (lesson[1]))#写入小节名
#提取小节中的资源(资源有视频,pdf等类型,我们只需要视频和pdf)
#pdf类型是3,视频类型1,正则需要用到
#首先提取视频资源信息(contentId,contentType,id,name),contentId和id我也搞不清楚,
#反正请求的时候要用到,就当作一个是资源本身id,一个是资源内容id
videoPattern=re.compile(r'contentId=(\d+).+contentType=(1).*?id=(\d+).*?lessonId='
+ lesson[0] + r'.*?name="(.+)"')
videoSet=re.findall(videoPattern,courseDetailInfo)#该小节下所有视频资源信息
#提取pdf资源信息
pdfPattern= re.compile(r'contentId=(\d+).+contentType=(3).+id=(\d+).+lessonId=' +
lesson[0] + r'.+name="(.+)"')
pdfSet=re.findall(pdfPattern,courseDetailInfo)#该小节下所有pfd资源信息
#我们把每个视频资源信息写入文件中,同时要把名字中特殊字符去除掉
#去除名字中特殊字符的正则
namePattern = re.compile(
r'^[第一二三四五六七八九十\d]+[\s\d\._章课节讲]*[\.\s、]\s*\d*')
#对每个视频资源信息做处理
count_num = 0#视频循环后就要循环pdf,为了让名字更有规律
for videoIndex, singleVideo in enumerate(videoSet):
rename = re.sub(namePattern,'',singleVideo[3])
#写入目录文件
file.write(' [视频] %s \n' % (rename))
#这个方法是对资源正真的处理,上面只是把名字写入目录
getContent(
singleVideo,'%d.%d.%d [视频] %s' %
(index+1, subIndex+1, videoIndex+1, rename)
)
count_num += 1
#对每个pdf资源信息做处理
for pdfIndex, singlePdf in enumerate(pdfSet):
rename = re.sub(namePattern,'',singlePdf[3])
file.write(' [文档] %s \n' % (rename))
getContent(
singlePdf, '%d.%d.%d [文档] %s' %
(index + 1, subIndex + 1, pdfIndex + 1 + count_num,
rename))
'''
@description: 对资源做具体处理
@param [tuple] singleResource 每个资源的具体信息(contentId,contentType,id,name),这些用来请求真实的资源信息
@param name 重新命名的资源名称
@return:
'''
def getContent(singleResource,name):
#我们对pdf直接下载,对视频保存下载地址
#检查是否有重名的pdf(即已经下载过的),如果有则不再获取资源
if os.path.exists('PDFs\\'+ name+'.pdf'):
print(name + "----------->已下载")
return
#正式获取资源下载地址
post_data={
'callCount': '1',
'scriptSessionId': '${scriptSessionId}190',
'httpSessionId': '5531d06316b34b9486a6891710115ebc',
'c0-scriptName': 'CourseBean',
'c0-methodName': 'getLessonUnitLearnVo',
'c0-id': '0',
'c0-param0': 'number:' + singleResource[0], # 二级目录id
'c0-param1': 'number:' + singleResource[1], # 判定文件还是视频
'c0-param2': 'number:0',
'c0-param3': 'number:' + singleResource[2], # 具体资源id
'batchId': str(int(time.time()*1000))
}
#获取资源,返回的还是一个ajax,但里面保存了真实的资源地址,所以还是要用正则提取
resouce=requests.post(getResourceUrl, headers=headers, data=post_data).text
#如果是视频资源,我们只保存下载链接
if singleResource[1]=='1':
#匹配视频下载地址的链接(其实有三种清晰度,我选了高清版的)
downloadPattern = re.compile(r'mp4ShdUrl="(.*?\.mp4).*?"')
videoDownUrl=''
#可能有些视频没有高清版,会抛出异常,所以捕获到异常,我们就存储普清的视频地址
try:
videoDownUrl=re.search(downloadPattern,resouce).group(1)
except :
#又可能某些视频没有普清版的,我们就下载标清版的视频地址
try:
download_pattern_compile = re.compile(r'mp4HdUrl="(.*?\.mp4).*?"')
videoDownUrl = re.search(download_pattern_compile,resouce).group(1)
except :
#如果标清的都没有,那么就直接结束,不要这个视频了(当然你也可以找下匹配规则)
try:
download_pattern_compile = re.compile(r'mp4SdUrl="(.*?\.mp4).*?"')
videoDownUrl = re.search(download_pattern_compile,resouce).group(1)
except:
return
#把下载地址写入文件
print('正在储存视频地址:' +name+'.mp4')
with open('Links.txt','a',encoding='utf-8') as file:
file.write('%s \n' % (videoDownUrl))
#我们下载的视频文件名是1006648121_526f81b110c845a3a1fd6ff4cc1331c1_shd.mp4这种格式,
#就算下载下来也不知道是什么视频,下面这段代码就是当你下载完了视频,通过批处理命令正确修改视频名称
with open('Rename.bat', 'a', encoding='utf-8') as file:
videoDownUrl = re.sub(r'/', '_', videoDownUrl)
file.write('rename "' + re.search(
r'http:.*video_(.*.mp4)', videoDownUrl).group(1) + '" "' +
name + '.mp4"' + '\n')
#如果是pdf资源,我们直接下载文件
else:
pdfDownUrl=re.search(r'textOrigUrl:"(.*?)"',resouce).group(1)
print('正在下载pdf:' +name+'.pdf')
pdf = requests.get(pdfDownUrl, headers=headers)
#如果是第一次下载要创建存储pdf的文件夹
if not os.path.isdir('PDFs'):
os.mkdir(r'PDFs')
with open('PDFs\\'+name+'.pdf','wb') as file:
file.write(pdf.content)
'''
估计很多人对于re.search()和re.findall()两个方法不理解,我来简单说下
re.search()和re.match()一样,都是返回Match对象.该对象包含了我们需要的匹配到的信息
如果没有则返回none. 但是re.search()只匹配第一个信息.非常适合匹配单个信息
re.findall()是返回一个数组对象, 该对象中包含了所有能被正则匹配的字符串, 非常适合匹配多个信息
'''
#我们的入口方法,组合上面写的代码就能愉快下载自己想要的课程
def main():
#因为是追加模式,所以要把保存课程目录的文件删除
if os.path.exists('MindMap.txt'):
os.remove('MindMap.txt')
#正式测试
courseCode='SICNU-1002031014'
courseId=getCourseBase(courseCode)#第一步
getCourseDetail(courseId)#第二步,第三步,第四步
完整实例代码在我的github上面下载
结束语
通过上面爬虫,我们就能下载中国mooc课程了, 可喜可贺.